How ChatStack AI Manages Context
Context Management refers to how the application handles the message history provided to the AI model. LLMs have evolved to be able to increase its awareness of past messages in a chat but are still far from having memory. It is the responsibility of the chat app to manage the past messages and communicate them in a sensible manner to the AI model.
Managing the chat history and providing the right context is one of the most challenging aspects of modern chat applications, as it has a deep impact in performance and cost:
- LLMs perform better if the information they receive is rich and adequate for the most recent message. As the chat grows, finding the right information becomes increasingly difficult, and having the right techniques to filter out the most valuable context.
- AI models are also limited by the amount of information they can handle. This imposes a hard-limit on how many tokens (messages) the chat application can share with the LLM. Therefore, smart ways to maximize the relevant content within the context limit is essential.
Check the context limit when choosing a model.
- Cost increases with the amount of tokens sent to the AI model. As a result, context management plays a key role saving tokens and money. Having good handling of past messages and relevant information for the current chat may result in massive cost reduction.
ChatStack AI Context Management
To optimize token savings and provide the most relevant information to the AI model, ChatStack AI combines three different techniques for context management.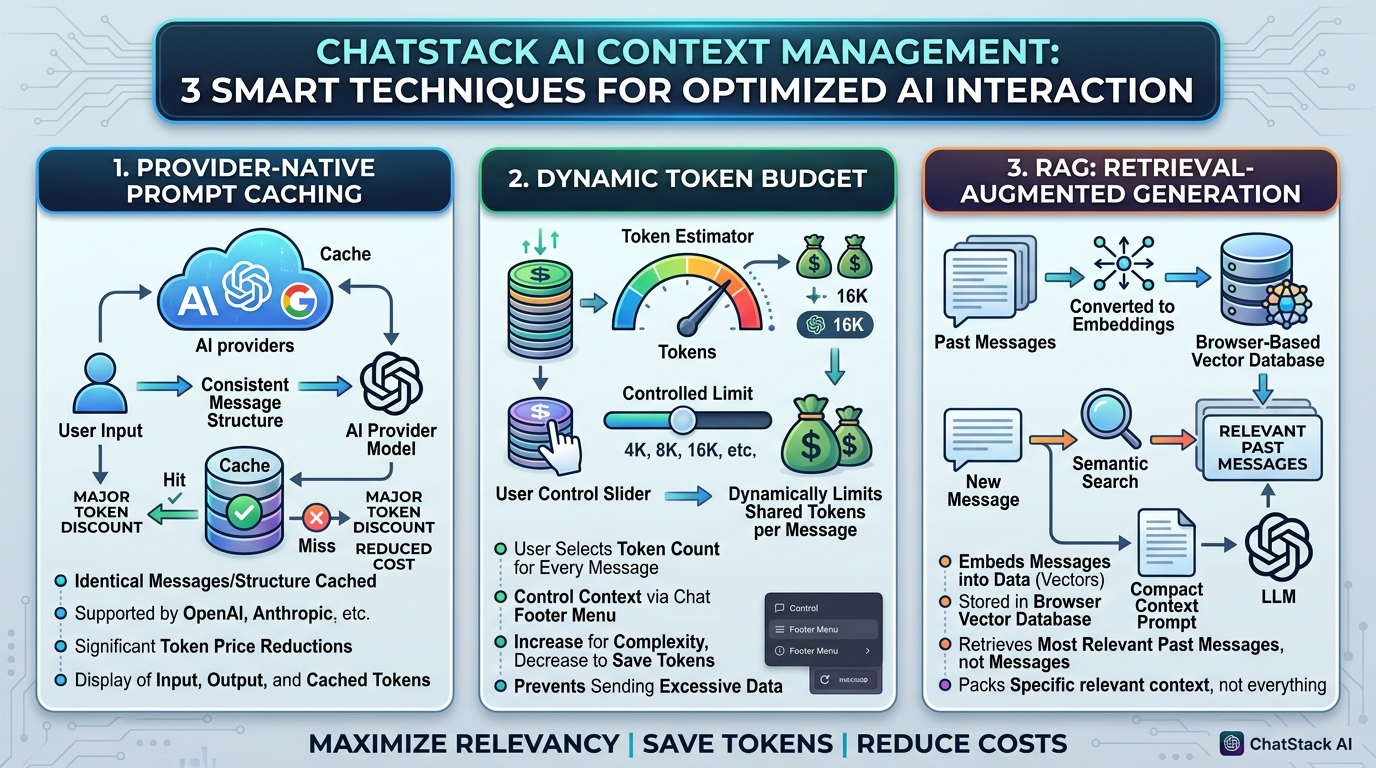
Provider-Native Prompt Caching
Most providers (OpenAI, Anthropic, Google, OpenRouter, and more) include in prompt caching their design. This means that when identical messages are sent following the same structure, the AI model caches the information and does not need to process the input from scratch. Cached tokens have major discounts (see the token prices in Models), which means that consistent formatting in how the messages are sent to the LLM lead to massive savings.ChatStack AI always formats the messages such that the AI models who support caching can taken advantage of it. In addition, AI messages always display the input, output and cached tokens used by each message. This allows you to see if the model you selected is using caching to save you valuable tokens.

Dynamic Token Budget
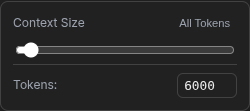
In ChatStack AI you can choose how many tokens you want to share with the AI model in each message. Sharing previous messages is a naive approach where you risk to send massive amount of data (tokens) with realizing, increasing the cost without reason. ChatStack AI implements a token estimator that allows you to control the context dynamically.Select the amount of tokens that you want to share for every message using the context menu in the chat footer. If a task is complex, you can momentarily increase it. If less information is needed, keep the context lower for saving some extra tokens.
RAG: Retrieval-Augmented Generation
Retrieval-Augmented Generation (RAG) is a machine learning technique that transforms messages in data forms that can be easily manipulated and stored in databased (for ChatStack AI this happens in your browser). This process is called embedding. Then, when you send a new message, it is possible to use these data to find the stored messages that are most relevant and share them with the AI model.In this way, ChatStack AI does not share all previous messages, it selects those that are more meaninfull for the current message and packs them together before sending them to the LLM. Therefore, when you select a dynamic token budget, a fraction of it is based on current information while the rest is a combination of the most relevant past messages.